HyPlag: Wuppertaler Forscher arbeiten daran, Plagiate zuverlässiger zu erkennen
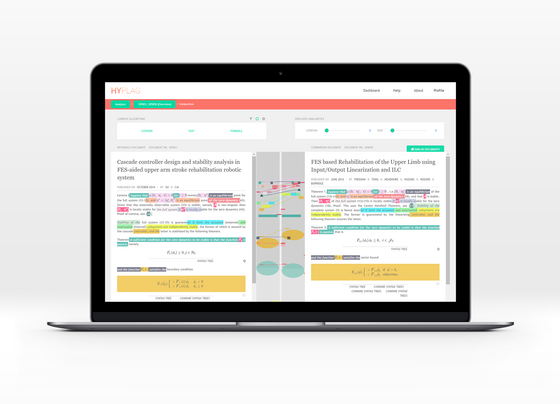
Das System „HyPlag“ geht über das reine Auffinden identischer Textstellen hinaus und identifiziert auch auffällige Ähnlichkeiten nicht-textueller Elemente.<br/><span class="sub_caption">Grafik Bela Gipp</span><br/><span class="sub_caption">Klick auf die Grafik: Größere Version</span>
Beim Einsatz von Softwaresystemen zur Plagiatserkennung müssen Nutzer*innen einiges bedenken. Effektivität und Bedienbarkeit weisen häufig Mängel auf. Liegen die Datenbanken der genutzten Anwendungen zudem auf Servern im Ausland, ist der Einsatz hinsichtlich des Datenschutzes problematisch, denn nicht immer ist klar, was genau mit den Dokumenten passiert oder welche Urheberrechte dabei an die Anbieter abgetreten werden.
„Bei HyPlag geht es zunächst darum, ein System zu entwickeln, das mehr leistet als den reinen Textvergleich. Um Ideen- oder Übersetzungsplagiate in Forschungspublikationen – wie z.B. in Zeitschriftenartikeln, Doktorarbeiten aber auch Stipendien- und Drittmittelanträgen – aufzudecken, müssen auch Bilder, Grafiken, Formeln und Quellenverweise überprüfbar sein“, erklärt Norman Meuschke, Wissenschaftlicher Mitarbeiter am Lehrstuhl für Data & Knowledge Engineering von Prof. Dr. Bela Gipp. Meuschke arbeitet im Rahmen seiner Promotion an der Entwicklung von HyPlag.
Auf Basis bestätigter Plagiate hat das System bereits viel gelernt: „Die Erkennung läuft gut“, bewertet Meuschke. HyPlag geht über das reine Auffinden identischer Textstellen hinaus: So ist das System bereits in der Lage, Paraphrasierungen zu erkennen. Außerdem arbeiten die Wissenschaftler derzeit daran, Verfahren zu integrieren, die erkennen, wenn sich der Schreibstil innerhalb eines Dokumentes ändert. „Solche Schreibstiländerungen können ein Hinweis auf nicht deklarierte Textübernahmen sein“, so Meuschke.
Dahinter stecken von den Forschern vorprogrammierte Algorithmen, ebenso wie maschinelle Lernverfahren. Die Benutzer*innen erhalten nach erfolgter Analyse eine Ergebnisübersicht zur schnellen Überprüfung von identifizierten Ähnlichkeiten sowie eine detaillierte Vergleichsansicht, um betroffene Dokumentstellen näher zu betrachten – darin enthalten sind dann eben nicht nur identische Textstellen, auch auffällige Muster in den verwendeten Quellenverweisen oder ein potenziell vorliegender Ideenklau beim Anfertigen einer Grafik wird markiert. „Die Analyse von nicht-textuellen Merkmalen, wie Quellenverweisen, Abbildungen und auch mathematischen Inhalten, hilft, ein großes Problem aktueller Systeme, die nur den Text analysieren, zu lösen: Übersetzungsplagiate“, erklärt Meuschke. Zu erkennen, dass Text aus einer anderen Sprache übernommen wurde, das war bisher kaum möglich. Auch Formeln würden aktuelle Systeme vollkommen ignorieren, was die Analyse mathematischer Publikationen enorm erschwert.
Mittelfristig soll HyPlag zu einer offenen Plattform entwickelt werden, die als Serviceleistung auch von anderen Universitäten genutzt werden kann. „Ziel ist es, einen unabhängigen Dienst aus öffentlicher Hand bereitzustellen. Damit ließen sich auch die Themen Datenschutz und Urheberrecht besser überblicken“, so Prof. Gipp. Doch bis es so weit ist, sind noch einige Entwicklungsschritte notwendig, die auch finanziert werden wollen. Meuschke: „Um eine solche Plattform zur Verfügung zu stellen, muss natürlich auch die IT-Infrastruktur passen. Zum Beispiel muss die Sicherheit der Nutzer*innendaten garantiert sein und sehr große Dokumentbestände so verwaltet werden, dass das System zu überprüfende Dokumente schnell mit ihnen vergleichen kann. Außerdem sollte das System leistungsfähig genug sein, um auch zahlreiche gleichzeitige Nutzer*innenanfragen verarbeiten zu können. Das bedeutet entsprechend viel Arbeit neben der reinen Entwicklung der Erkennungsalgorithmen.“ Um diese Pläne weiter verfolgen zu können, laufen bereits die Anträge für Fördergelder bei der Deutschen Forschungsgemeinschaft (DFG).
„Eine Software alleine kann nie in der Lage sein, über Plagiate zu entscheiden. Aber wir können damit das System anbieten, um eine Expert*innenkommission, die im Verdachtsfall weitere Entscheidungen treffen muss, zu unterstützen und ihre Arbeit um ein Vielfaches zu erleichtern“, betonen Gipp und Meuschke.
Kontakt:
Norman Meuschke
Lehrstuhl für Data & Knowledge Engineering
E-Mail meuschke[at]uni-wuppertal.de
Telefon 0202/439-1618